
Running OCR against a PDF file with AWS Textract
Textract is the AWS OCR API. It’s very good - I’ve fed it hand-written notes from the 1890s and it read them better than I could.
It can be run directly against JPEG or PNG images up to 5MB, but if you want to run OCR against a PDF file you have to first upload it to an S3 bucket.
Update 30th June 2022: I used what I learned in this TIL to build s3-ocr, a command line utility for running OCR against PDFs in an S3 bucket.
Try it out first
You don’t need to use the API at all to try Textract out against a document: they offer a demo tool in the AWS console:
https://us-west-1.console.aws.amazon.com/textract/home?region=us-west-1#/demo
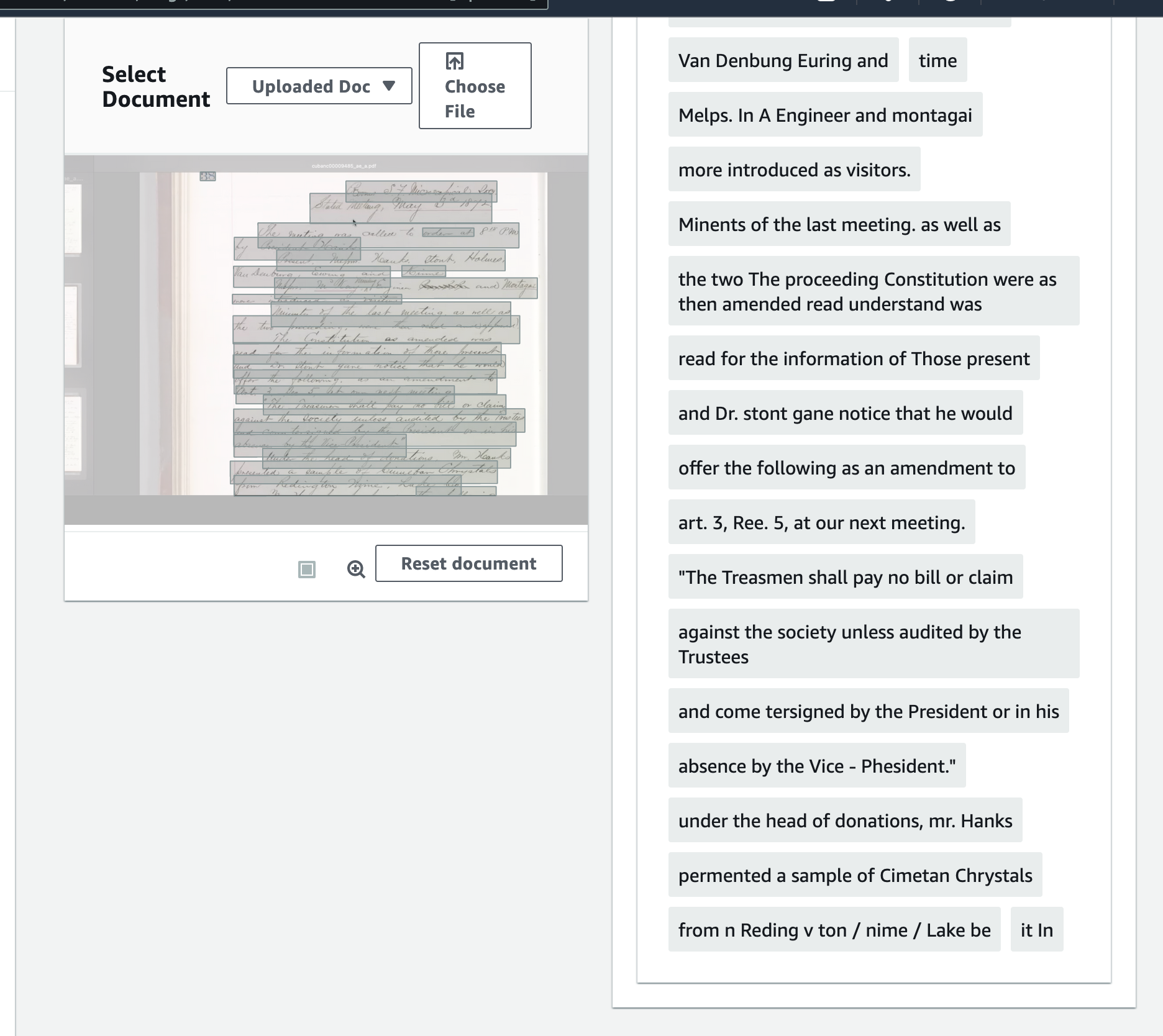
Limits
Relevant limits for PDF files:
For asynchronous operations, JPEG and PNG files have a 10MB size limit. PDF and TIFF files have a 500MB limit. PDF and TIFF files have a limit of 3,000 pages.
For PDFs: The maximum height and width is 40 inches and 2880 points. PDFs cannot be password protected. PDFs can contain JPEG 2000 formatted images.
Uploading to S3
I used my s3-credentials tool to create an S3 bucket with credentials for uploading files to it:
~ % s3-credentials create sfms-history -cCreated bucket: sfms-historyCreated user: 's3.read-write.sfms-history' with permissions boundary: 'arn:aws:iam::aws:policy/AmazonS3FullAccess'Attached policy s3.read-write.sfms-history to user s3.read-write.sfms-historyCreated access key for user: s3.read-write.sfms-history{ "UserName": "s3.read-write.sfms-history", "AccessKeyId": "AKIAWXFXAIOZBOQM4XUH", "Status": "Active", "SecretAccessKey": "...", "CreateDate": "2022-06-28 17:55:10+00:00"}I stored the secret access key in 1Password, then used it in Transmit to upload the PDF files.
Starting a text detection job
For PDFs you need to run in async mode, where you get back a job ID and then poll for completion.
You can ask it to send you notifications via an SNS queue too, but this is optional. You can ignore SNS entirely, which is what I did.
To start the job, provide it with the bucket and the name of the file to process:
import boto3
textract = boto3.client("textract")response = textract.start_document_text_detection( DocumentLocation={ 'S3Object': { 'Bucket': "sfms-history", 'Name': "Meetings and Minutes/Minutes/1946-1949/1946-10-04_SFMS_MeetingMinutes.pdf" } })job_id = response["JobId"]Polling for completion
You can then use that job_id to poll for completion. The textract.get_document_text_detection call returns a JobStatus key of IN_PROGRESS if it is still processing.
Here’s a function I wrote to poll for completion:
import time
def poll_until_done(job_id): while True: response = textract.get_document_text_detection(JobId=job_id) status = response["JobStatus"] if status != "IN_PROGRESS": return response print(".", end="") time.sleep(10)
# Usage, given a response from textract.start_document_text_detection:completion_response = poll_until_done(response["JobId"])This can take a surprisingly long time - it took seven minutes for a 6 page typewritten PDF file for me, and ten minutes for a 56 page handwritten one.
I was wondering how long you have to retrieve the results of a job. The get_document_text_detection() documentation says:
A
JobIdvalue is only valid for 7 days.
Fetching the results
The response that you get back at the end is paginated. Here’s a function to gather all of the “blocks” of text that it detected across multiple pages:
def get_all_blocks(job_id): blocks = [] next_token = None first = True while first or next_token: first = False kwargs = {"JobId": job_id} if next_token: kwargs["NextToken"] = next_token response = textract.get_document_text_detection(**kwargs) blocks.extend(response["Blocks"]) next_token = response.get("NextToken") return blocks(I could have used this boto3 pagination trick instead.)
Blocks come in three types: LINE, WORD, and PAGE. The PAGE blocks do not contain any text, just indications of which lines and words were on the page. The LINE and WORD blocks duplicate each other - you probably just want the LINE blocks.
Here’s an example of a LINE block:
{ "BlockType": "LINE", "Confidence": 90.4699478149414, "Text": "1", "Geometry": { "BoundingBox": { "Width": 0.00758015550673008, "Height": 0.011477531865239143, "Left": 0.9904273152351379, "Top": 0.00909337680786848 }, "Polygon": [ { "X": 0.9904273152351379, "Y": 0.00909337680786848 }, { "X": 0.9980074763298035, "Y": 0.00909337680786848 }, { "X": 0.9980074763298035, "Y": 0.0205709096044302 }, { "X": 0.9904273152351379, "Y": 0.0205709096044302 } ] }, "Id": "6b04b8df-bec1-42d3-bfff-29f0edd38976", "Relationships": [ { "Type": "CHILD", "Ids": [ "58890ca7-5ed5-4b14-ad60-475e5d0dd79e" ] } ], "Page": 1}I found that joining together those lines on a \n gave me the results I needed:
print("\n".join([block["Text"] for block in blocks if block["BlockType"] == "LINE"]))Truncated output:
1ORGANIZATION MEETINGof theSAN FRANCISCO MICROSCOPICAL SOCIETYOctober 4, 1946The meeting ws.s held at 8:00 P.M. on October 4, 1946, in theAuditorium of the San Francisco Department of Health, 101 Grove Street,San Francisco.Chairman George Herbert Needham called the audience of sixty-five persons to order. He told of the high aims, ideals, and fine fellow-ship enjoyed by the original society which was organized in 1870 and incor-porated in 1872, but which was dissolved following the San Francisco fireof 1906. He related his efforts to find a surviving member which finallyresulted in a telegram of greeting from Dr. Kaspar Pischell of Ross, Cali-fornia, which read as follows:"BEST WISHES AT THIS REUNION. I AM SORRY I CANNOT BE WITH YOU."